The equation with unknowns: assessing the complexity of machine learning projects
Not every problem should be solved using machine learning (ML). Attempts to break this rule are common because of the extreme popularity of ML in recent years and the increasing availability of computational resources. Machine learning makes sense when the problem has no explicit algorithmic solution, i.e. you cannot explicitly set the solution conditions and describe explicitly the result you are going to achieve if the given conditions are met. Solving algorithmic problems using ML is possible, but it will often require more computational resources than the "head-on" approach.
In this article we will consider the parameters and approaches for estimating the cost of ML projects, putting aside the evaluation of software development and the solution of various optimization problems.
What's important to know about machine learning projects
-
A high degree of uncertainty. Unlike software development projects, where it is often possible to precisely define requirements and complete the program development, ML projects usually require several iterations in gathering requirements, refining model quality metrics, and other project inputs. Often the project customer cannot, for objective reasons, accurately describe the image of the result, or important details are identified in the course of the project that transform, refine that image.
-
Dependence on data quality. The results of the ML project depend largely on the quality of the data used to train the model. Not in every data set it will be possible to find the dependences useful for business awareness and development, for automation of routine actions, therefore before the start of the project it is important to analyze the available data. In addition, you need to consider possible errors, outliers, and omissions in the data when estimating the labor intensity of the project.
-
Importance of Prototyping. Among the stages of ML-projects it is important to distinguish the construction of a prototype solution, after which the decision on its further continuation and labor intensity is much easier to make with the support of viable data and algorithms. It is worth noting that customers often try to ignore this stage and do not accept its value to their business.
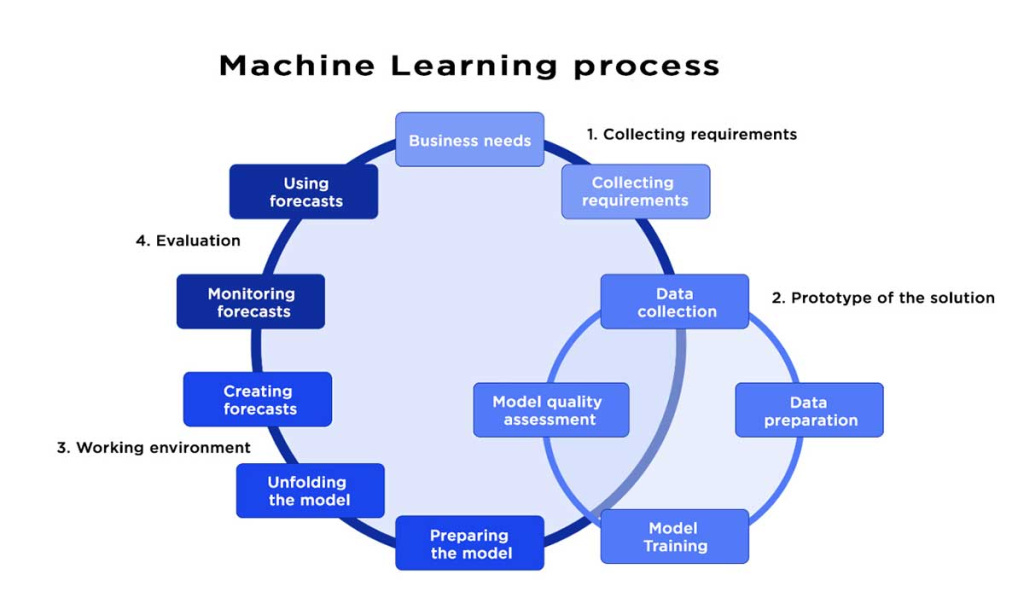
-
The need to work with large amounts of data and the high demand on computing resources. ML projects typically use large amounts of data to train models and assess their quality. This can affect the time/computational resources required to load, process, and analyze the data.
- Need for expert opinion. ML projects often require expert (domain) opinion to understand the specifics of the data, the semantic content of the data attributes, and to evaluate model quality and select optimal algorithms and parameters. This can affect the time it takes for the team to be triggered and the qualifications of the personnel involved in the project.
To summarize the above and conclude that it is difficult to predict the outcome of a machine learning project before it begins, requiring significant computing power and scarce expertise, which, in addition, increases the cost of the project at its already high risk.
Parameters for estimating the labor intensity of ML projects
With all the complexity and uncertainty of ML project estimation, it needs to be done every time a customer comes with their task.
Often, labor intensity depends on a variety of factors, such as:
-
The size of the data and its representation. The amount of data required to train a model significantly affects the labor intensity of a project. The more data required for training, the more time and resources it will take to train the model.
-
The quality of the data inevitably affects the labor intensity of the project. Up to 50% of the project time, and sometimes more, can be spent preparing the training set. The selection of data enrichment strategies, different approaches to filling in missing values all affect the quality of the final model, and therefore require significant attention from ML engineers.
-
Task and model complexity. ML tasks come in all kinds of complexity, requiring different methods, approaches, and combinations of them. In order for models to properly assimilate the complex dependencies hidden in the data, the models themselves become more complex, using ensembles and combinations of them. Obviously, it takes more time to select the architecture of a complex solution as well as to tune its parameters than for simple solutions.
- Technology Stack. Some tools can simplify data and model learning. For example, AutoML class solutions speed up the process of data preparation, model training and model tuning. We like to use such solutions at project startup and POC preparation to make the cost of the initial project stage more interesting for the client and accelerate the decision on further investment in the project.
Ways to estimate the labor intensity of ML projects
The following is a look at some of the approaches to estimating the labor intensity of ML projects that we use in practice.
-
Decomposition of a project into separate tasks. The decomposition is usually based on the functionality that the client needs and expects to see at the end of the project. Each task is then evaluated based on previous experience or expert opinion. The estimate is made based on the time it takes to complete the task. Adding up the labor-intensive estimates, you get an overall estimate.
-
Expert evaluation. Here we involve experienced colleagues with an experience profile relevant to the task at hand. This is not only engineers in the field of ML, but also domain specialists from areas such as retail, finance, agribusiness, etc. The experience and opinions of colleagues from different areas overlap well, "overpollinate".
The following methods are more interesting. I would call them - "cobbler with boots," since the ML project labor intensity assessment is carried out with the use of ML.
-
Statistical analysis. The method involves analyzing data from past projects on the parameters listed above (and not only). Regression models built on such data take new project data as input and help make cost decisions. We have experience in training models to predict individual parameters of project evaluation, for example, prediction of developers' labor cost depending on their region, qualification, stack, etc.
-
Decision trees. The method involves the creation of a decision tree, where each branch represents a certain factor (data volume, model complexity, number of stages, etc.) affecting the labor intensity of the project. Each factor has its own weight, which is determined on the basis of past experience and expert opinion from the training data.
Thus, the main feature of ML-project evaluation is weak predictability of its result. At the initial stages this result is clarified, the criteria for its evaluation is detailed, a basic model is built, which reduces the risks of both the customer and the executor. However it is worth noting that Russian business does not like to fund the research stages of ML-projects, which is almost the main reason of conflict between customer and contractor. At the same time, having passed the research stage of the project the customer may already receive insights on the points of growth of their business, even before complex models are built.
In complex projects, which are difficult to estimate, machine learning models trained on data from previous projects are helpful. This allows you to take into account hidden dependencies between project parameters and "insure" the loss of time on seemingly implicit tasks.